
파싱에 대해 알아보자.
파싱 (Parsing)
문서 파싱은 브라우저가 코드를 이해하기 쉽고, 사용하기 쉬운 구조로 변환하는 것을 말합니다.
파싱 결과는 보통 문서 구조를 나타내는 노드 트리입니다. (파싱 트리, 문법 트리)
예를 들면, 2 + 3 - 1 을 파싱해보면 다음과 같은 노드 트리가 됩니다.
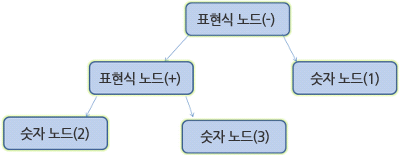
어휘 분석, 구분 분석
파싱은 어휘 분석과 구문 분석으로 구분합니다.
어휘 분석 (토큰 변환)
자료를 Token으로 분해하는 과정을 말합니다.
Token : 유효하게 구성된 단위의 집합체
구문 분석
언어의 구문 규칙을 적용하는 과정을 말합니다.
파서는 두가지 일을 합니다.
- 유효한 토큰으로 분해하는 어휘 분석기
- 언어 구문 규칙에 따라 문서 구조를 분석해 파싱 트리를 생성
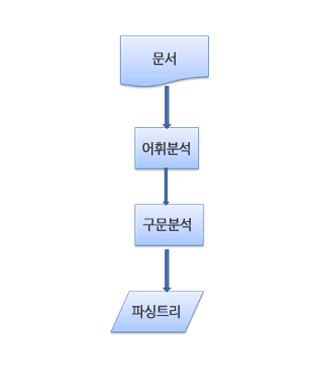
즉, 어휘 분석기로부터 새 Token을 받아서 구문 규칙과 일치하는지 확인하고 일치한다면 노드가 파싱 트리에 추가됩니다.
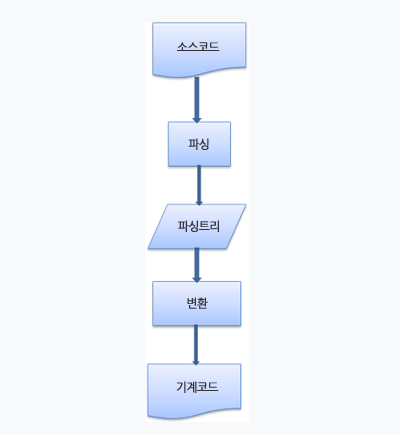
파서로 생성된 파싱 트리는 최종 결과물이 아니고 이후 변환 과정이 필요합니다.
(예시 : 컴파일)
컴파일 : 소스 코드를 기계 코드로 만드는 컴파일러는 파싱 트리 생성 후 이를 기계 코드로 변환합니다.
파서의 종류
상향식 파서
구문의 하위 구조부터 일치하는 부분을 찾습니다.
하향식 파서
구문의 상위 구조부터 일치하는 부분을 찾습니다.
HTML 파서
HTML 마크업을 파싱 트리로 변환하는 파서로, HTML 문법은 W3C에 의해 명세로 정의되어 있습니다.
HTML에는 적통적인 파서를 적용할 수 없습니다.
이유는 HTML의 공식적인 형식인 DTD는 BNF 형식으로 완전히 표현할 수 없기 때문입니다.
BNF : 문맥 자유 문법(Context-Free Grammar)을 기술하기 위해 만든 표기법 <기호> ::= <표현식> 형태로 정의
즉, 일반적인 상향식, 하향식 파서로 파싱할 수 없습니다.
이유
- 언어의 유연한 속성 (암묵적인 태그 생략 등)
- HTML 오류에 대한 브라우저의 관용
- 변경에 의한 재파싱이 잦음
파싱 알고리즘
일반적인 파싱 기술을 사용할 수 없는 HTML을 파싱하기 위해 브라우저가 생성한 별도의 파서를 사용합니다.
이는 토큰화와 트리 구축 2단계로 구성됩니다.
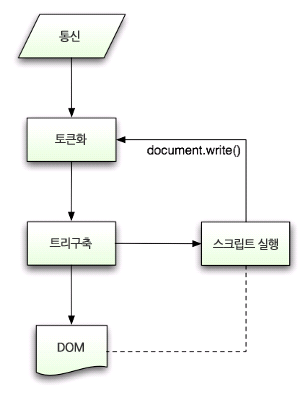
토큰화 알고리즘 (Tokenizer)
어휘 분석으로 입력 값을 토큰으로 파싱합니다.
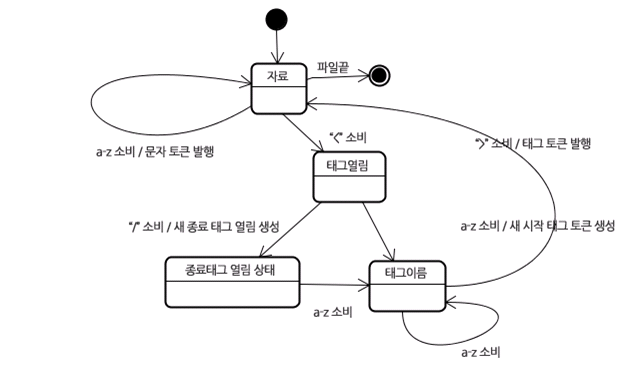
결과물은 시작 태그, 종료 태그, 속성 이름, 속성 값 입니다.
시작 태그
초기 상태는 “자료 상태”
< 를 만나면 “태그 열림 상태”
a-z 문자 를 만나면 “태그 이름 상태”
> 를 만나면 현재 토큰을 발행하고 다시 “자료 상태”문자 토큰
“자료 상태” 에서 a-z를 만나면 문자 토큰 생성
<를 만나면 문자 토큰 발행 후, “태그 열림 상태”종료 태그
“태그 열림 상태” 에서 /를 만나면 “종료 태그 토큰” 을 생성하고 “태그 이름 상태”
>를 만나면 토큰 발행 후 “자료 상태”
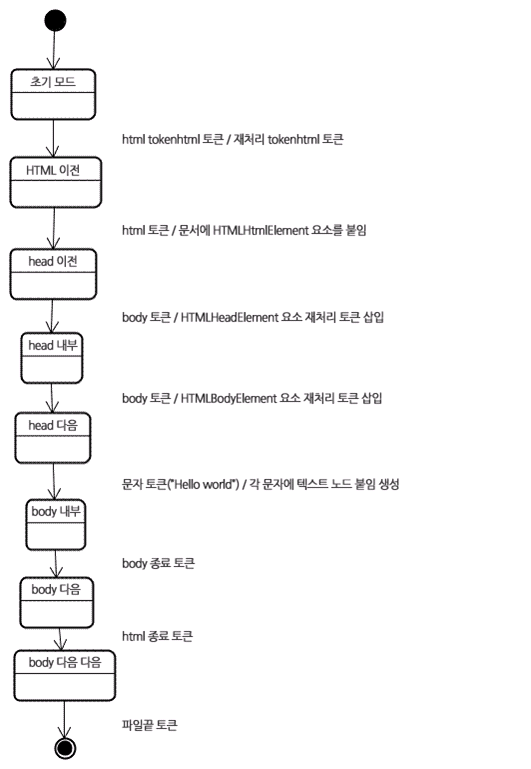
트리 구축 알고리즘
- 파서가 생성되면 문서 객체가 생성
- 트리 구축이 진행되면서 문서 최상단에서는 DOM 트리가 수정되고 요소가 추가
- 토큰화에 의해 발행된 각 노드는 트리 생성자가 처리
- DOM 트리에 요소를 추가하는 것이 아니라면 열린 요소는 스택에 저장, 부정확한 중첩과 종료되지 않은 태그를 교정
- 알고리즘은 상태 기계
- 상태는 삽입 모드
참조
- https://velog.io/@0_sujeong/%EC%9D%B8%ED%84%B0%EB%84%B7%EB%B8%8C%EB%9D%BC%EC%9A%B0%EC%A0%80%EC%9D%98-%EC%9E%91%EB%8F%99-%EC%9B%90%EB%A6%AC2-%ED%8C%8C%EC%8B%B1%EA%B3%BC-DOM-%ED%8A%B8%EB%A6%AC-%EA%B5%AC%EC%B6%95
- https://ko.wikipedia.org/wiki/%EA%B5%AC%EB%AC%B8_%EB%B6%84%EC%84%9D
- https://blog.binple.net/98